

Inside the VLAM Stack: Building Generalist Agents That See, Understand, and Act
As the frontier of artificial intelligence shifts from text and images to machines that perceive and act in the physical world, a new class of models is emerging at the center of physical AI: vision-language-action models (VLAMs). These robust systems fuse what an agent sees, what it understands through language, and how it acts, all within a unified architecture. In doing so, they promise a path to generalist agents capable of adapting to many tasks with minimal retraining, a dramatic leap beyond today’s specialized, rule-based AI systems.
Why are researchers and companies betting on VLAMs? They offer a way to break the silos that have long defined how AI works in the physical world, enabling systems that can follow flexible instructions, generalize to new scenarios, and learn from limited examples. However, building these models and deploying them in real-world environments requires rethinking every layer of the AI stack, from representation learning and control theory to data collection and safety engineering.
To unpack how VLAM agents are redefining the foundation model stack in physical AI, we spoke with Prof. Honglak Lee, a leading researcher in AI, deep learning, and representation learning. His work sheds light on both the breakthroughs and the challenges in bringing these powerful models to life.
VLAMs (Vision-Language-Action Models) Explained
But before we get into our conversation with Prof. Lee, let’s dive a bit into what exactly VLAMs are and why they’re essential. VLAMs, or Vision-Language-Action Models, are a new class of AI systems designed to perceive, understand, and act in the physical world.
They integrate three core components:
- Vision: The model processes visual input from cameras or sensors to perceive its environment.
- Language: It interprets natural language instructions, questions, or contextual cues.
- Action: It decides and executes physical actions, such as moving, picking up objects, or manipulating tools.
Why VLAMs Matter
Traditional AI systems often separate these components—one model for perception, another for planning, another for control. VLAMs fuse them into a single, unified model, usually using a transformer-based architecture.
This allows VLAMs to:
- Generalize across environments without retraining from scratch
- Follow flexible natural language commands (e.g., “bring me the red cup from the kitchen”)
- Adapt to new tasks with few or no new examples (few-shot or zero-shot learning)
In short, VLAMs represent a step toward generalist AI agents that can understand their surroundings, interpret instructions, and carry out physical tasks, just like humans do.
How VLAM Models Combine Sensing and Acting in Generalist Agents
Ashutosh Saxena: Researchers are turning to vision-language-action models (VLAMs) to build agents that go beyond rigid, pre-programmed scripts by bridging the gap between what an agent sees and understands through language and how it decides to act. VLAMs enable embodied AI systems to interpret complex environments and respond to flexible instructions by fusing these modalities into a unified policy. How do VLAMs integrate perception and control in practice, and what makes this integration more transformative than traditional software AI pipelines?
Prof. Honglak Lee: Modern VLAMs typically use a transformer-style architecture that integrates multiple input modalities—visual frames, language instructions, and sometimes proprioceptive signals—into a unified sequence. These inputs are embedded and processed together, and the model outputs an action token that can represent either low-level commands, such as joint torques, or higher-level abstract API calls.
This approach enables end-to-end, autoregressive decision-making in real time. It’s a significant shift from traditional AI pipelines that treat perception, reasoning, and control as separate modules. With VLAMs, all of these components are fused into a single model that can be trained directly from expert demonstrations or supervised trajectories.
Another transformative aspect is the ability to leverage large-scale pretraining. We now have powerful vision, language, and vision-language models that provide rich abstractions of both visual scenes and linguistic instructions. VLAMs build on this foundation, adapting these pretrained models to action-generation tasks—essentially replacing the output modality (from text to actions) while still benefiting from the generalization capabilities of the original models.
This type of transfer learning—pretraining on broad domains and adapting to specific tasks—has been a core driver of progress in deep learning. In the context of robotics, it means we can now combine high-level planning from language models with the perception capabilities of vision models, all in a framework that can produce physical actions. This fusion enables agents to reason abstractly, plan intelligently, and act effectively in complex real-world environments.
Ashutosh Saxena: Would you say it’s fair—especially in light of your work on representation learning—that transformers are particularly good at cross-modal representation learning, something that previously had to be done manually?
Prof.Honglak Lee: Yes. Transformers can be viewed as a unified architecture that processes input tokens—whether they originate from vision, language, or proprioception—and produces output tokens within a consistent framework. In a way, it’s similar to an autoencoder, where the model compresses and abstracts complex multimodal input into a shared internal representation. That internal abstraction is what enables the model to output meaningful responses, whether it’s an action in the real world or an answer to a question. This implicit representation learning across modalities is what makes transformers especially powerful for VLAMs and embodied AI systems.
Why Few-Shot and Zero-Shot Learning Are Key for Real-World AI
Ashutosh Saxena: Let’s shift to the topic of few-shot and zero-shot learning. These techniques are increasingly critical for real-world deployment, especially in robotics, where collecting and labeling enough diverse data for every possible scenario is often impractical—or even dangerous. Prof. Lee, how does few-shot learning work when implementing AI solutions, and why is your research on unsupervised and label-efficient methods so crucial for making physical AI viable in the real world?
Prof. Honglak Lee: That’s a great question. A key enabler for few-shot learning is having strong underlying representations. My research has focused heavily on learning abstract visual and multimodal representations—ways of capturing meaningful structure from raw inputs, such as pixels or text. When models can recognize abstract patterns or parts within complex data, they become far more capable of generalizing from just a few examples.
One area I’m particularly excited about is applying large language models for few-shot planning. Everyday household tasks, for example, involve compositional structure—things like picking up different objects, opening containers, or combining tasks like throwing out the trash while making coffee. These tasks can often be broken down into reusable atomic actions. Large models can learn these action patterns from just a few examples and then generalize to new, unseen sequences.
In earlier work, we demonstrated how large models could perform few-shot planning by reusing familiar action sequences in novel contexts. We’ve also combined visual, linguistic, and temporal representations to help agents learn subtask-aware behaviors, such as breaking a long human demonstration into more straightforward steps like opening a door or grasping a handle. From there, we can even derive implicit reward functions based on visual and task cues, helping agents understand whether they're succeeding without explicit labels.
Ashutosh Saxena: That’s amazing, because what you’re describing captures two fundamental ideas. First, there’s the general principle in AI that, given a task and a reward, an agent can learn to solve it. But your innovation goes a step further: instead of thinking at the level of raw pixels or motor torques, you're working with high-level concepts and structure—steps like “do 1, 2, 3, 4”—which allow the model to reason and generalize. That’s the heart of your compositional generalization work.
Prof. Honglak Lee: Exactly. And what’s especially exciting now is how the latest generation of foundation models strengthens this. Large language models are incredibly powerful engines for compositional tasks—they can not only plan naturally, but translate those plans into low-level steps with detailed descriptions. And with VLAMs, we’re extending that capability into the physical world. These models can interpret language and visual cues and directly produce actions. That’s a really exciting direction for physical AI.
Why Representation Learning Is Key for Generalist Agents
Ashutosh Saxena: Representation is one of physical AI’s most important—and often overlooked—components, as it determines how an agent transforms raw sensory inputs like images, depth maps, or force readings into structured information it can reason about and act upon—without which even the most powerful models struggle to interpret the physical world or generalize beyond their training data. Given your influential work on hierarchical and compositional representations, Prof. Lee, what does “representation” mean in the context of physical agents, how do models abstract sensor data, and how do hierarchical and compositional structures enable generalization across tasks?
Prof. Honglak Lee: In the context of physical agents, representation learning goes beyond general visual understanding—it involves building structured, often 3D, internal models of the world. While understanding 2D images is important, it’s even more valuable for agents to learn implicit 3D representations of their environments. These representations allow the agent to reason about space, geometry, and physical interactions in a more native, intuitive way.
There are many approaches to modeling 3D—some involve explicit, handcrafted representations, while others use neural networks to build implicit 3D models from 2D input. My research has explored how transformer-based architectures can learn such representations by encoding partial 3D observations and reconstructing the whole scene. This type of learned 3D understanding is essential for performing physical tasks that involve interacting with the environment, like grasping objects, navigating tight spaces, or opening containers.
Just as language models build an intuitive understanding of linguistic structure, and vision transformers do the same for images, I believe we need similar native architectures for 3D. These can help agents understand scenes not just in terms of pixels, but in terms of surfaces, objects, and affordances.
Another area I find promising is video prediction, which ties into the concept of world models. Here, the goal is to predict how the environment will evolve based on past observations and potential future actions. If a robot can simulate how its actions might unfold—visually and physically—it can reason more safely and effectively. This helps with long-term planning and prevents unsafe scenarios from occurring.
While transformer-based VLAMs are highly efficient for mapping input to action, combining them with predictive simulation capabilities can significantly enhance safety and handling of task complexity. By simulating multiple futures and choosing the most reasonable or optimal one, agents can better manage real-world uncertainty and make more informed decisions.
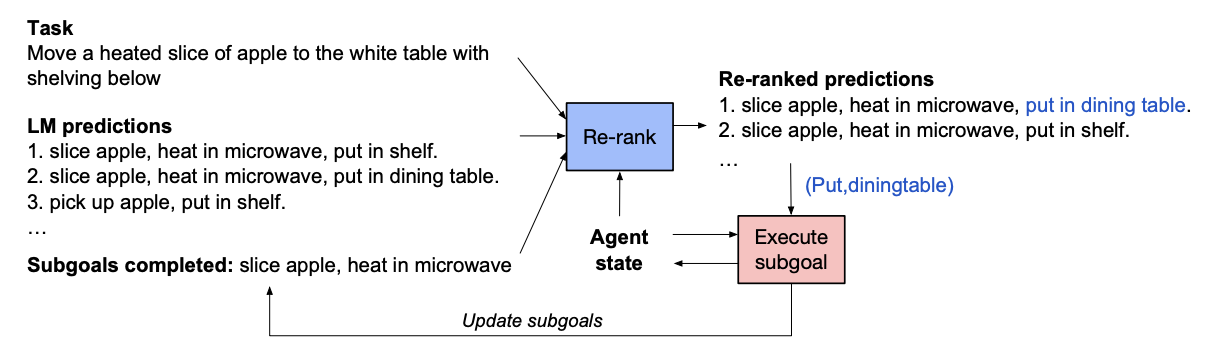
Image source: Lajanugen Logeswaran, Yao Fu, Moontae Lee, Honglak Lee “Few-shot Subgoal Planning with Language Models” Published May 28, 2022.
Early Work on AI for Robotics
Ashutosh Saxena: You and I co-authored a paper on learning visual representations for robotic grasping, which later received a ten-year test-of-time award for its role in bringing deep learning into robotics. Could you reflect on what made that work impactful and what you learned during that process that still feels relevant today?
Prof. Honglak Lee: It was an exciting and influential collaboration, mainly because it came at a time when deep learning was still in its early stages. Around then, deep neural networks were just starting to show promise in computer vision—ImageNet had recently been won by a deep CNN (Convolutional Neural Network) —but very little had been done to apply those techniques in robotics.
At the time, robotics was considered a much harder domain. It involved not just recognizing images but reasoning about physical environments, motor control, and handling cluttered, dynamic scenes. Our approach focused on learning unsupervised visual representations using a novel autoencoder architecture. That representation allowed a robot to predict grasp points from raw images—essentially enabling it to decide where and how to pick up objects.
This was one of the first demonstrations that deep learning could be helpful not just for perception, but for enabling physical action. It demonstrated that neural networks can learn directly from robotics data and perform well in tasks involving real-world complexity.
Looking back, the significance of that work was in showing the potential for deep learning to generalize across both vision and control, and in helping to open the door for an entire generation of deep learning-based approaches in robotics that followed.
Ashutosh Saxena: What makes you excited about the work we’re doing at TorqueAGI?
Prof. Honglak Lee: What excites me about TorqueAGI is the combination of deep expertise in both AI and robotics, along with a strong focus on solving real-world problems. You’re not just advancing research—you’re applying cutting-edge techniques in representation learning and embodied AI to real deployments.
I’ve been especially impressed by the way Torque is bridging foundational AI research with practical applications. You're tackling some of the most challenging tasks in robotics and making significant progress toward scalable, customer-ready solutions. That focus on both innovation and impact is what sets Torque apart, making the work especially compelling.

Image source: Ian Lenz, Honglak Lee, and Ashutosh Saxena “Deep Learning for Detecting Robotic Grasps”, Robotics Science and Systems (RSS), 2024. (Ten Year Test of Time Award)
From Research to Reality: What VLAMs Need Next
The rise of VLAM agents and foundation models marks a turning point for physical AI. By integrating perception, language understanding, and action in a single architecture, these systems promise to break free from the rigid constraints of traditional robotics, unlocking generalist agents that can adapt, learn, and perform in complex, dynamic environments.
Yet, realizing this vision depends on more than scaling up models. It demands advances in how we represent real-world data, develop label-free and few-shot learning techniques, and gather diverse, high-quality examples that reflect the messiness of the physical world. Without these foundations, general-purpose agents will remain stuck in the lab.
As Prof. Honglak Lee puts it:
“The next frontier is building agents that don’t just imitate tasks but understand and reason about their environments. By combining better representations with data-efficient learning, we can create systems that truly generalize—and bring embodied AI out of research and into the real world.”
The future of AI isn’t just about seeing and speaking; it’s about acting responsibly and intelligently in the world around us.
Whether you’re dealing with dynamic environments, moving objects, or difficult weather conditions, TorqueAGI is ready to add even more intelligence to your robotic stack. Contact us to schedule a demo and see how we can help!




