

Ashutosh Saxena, CEO of TorqueAGI and a pioneer in robotics and AI, sits down with Aditya Jami, Chief Technology Officer at Meltwater and former Big Data and Infrastructure leader at Netflix and Yahoo, for a deep dive into the evolving landscape of AI infrastructure.
Aditya is widely recognized for his contributions to large-scale, fault-tolerant systems, including the development of Chaos Monkey and the Simian Army at Netflix, as well as co-creating Priam to manage petabyte scale Cassandra clusters. These innovations laid the groundwork for today’s resilient cloud services and data platforms. Now, as AI moves beyond the digital realm into the physical world—with foundation models —the demands on infrastructure are shifting dramatically.
In this conversation, Ashutosh explores with Aditya what it takes to build infrastructure for intelligent, autonomous systems: infrastructure that’s not just scalable, but adaptive, embodied, and capable of supporting real-time learning and interaction. Together, they discuss how lessons from distributed systems, chaos engineering, and large-scale data architectures can inform the next generation of AI-native infrastructure, designed not just to deliver content or data, but to support generalist agents that think, act, and evolve.
Building AI Infrastructure for Scale in Cloud Environments
Ashutosh Saxena: At Netflix, you helped build some of the most resilient distributed systems in production, including tools like Priam and Chaos Monkey. How did that experience shape your view of what “large-scale AI infrastructure” should look like today?
Aditya Jami: My time at Netflix instilled core beliefs about cloud-scale systems that directly inform my view of AI infrastructure today. Three principles can summarize this:
- Embrace failure as a first-class citizen — Chaos-as-Code:. In AI infrastructure, this means injecting faults across GPUs, data pipelines, and model-serving clusters to validate the robustness of these systems. We simulate failures—dropping GPUs, corrupting training shards, partitioning networks—to ensure systems degrade gracefully and models perform under real-world adversity.
- Automate operational complexity — Self-Healing Data Fabrics: Priam automated Cassandra backup, scaling, and recovery. Today, we achieve this by using auto-scaling model replicas, patching frameworks (e.g., TensorFlow, PyTorch), and auto-rollbacks when drift is detected. Federated data meshes now heal embedding stores and document indices in response to schema or distribution shifts, using tools like Feast.
- Observable, declarative infrastructure — Observability for Model Health: Infrastructure should be declarative, defining the desired state and allowing systems to maintain it. In AI, this means pipelines with real-time telemetry on data skew and prediction quality. Declarative metadata policies —on features, skew, and embedding stability—help detect drift early.
These lessons compel us to view AI not just as an enabler but a critical, resilient part of a system that is continuously tested, observed, remediated, and an evolving element of your robotic stack.
From Cloud to Edge - Building AI-Native Infrastructure for Physical AI
Ashutosh Saxena: There’s a big shift happening—from large-scale cloud compute to intelligent agents operating on the edge, like robots. How do you think about orchestrating the balance between centralized and distributed agents for decentralization in AI infrastructure?
Aditya Jami: Orchestration in a hybrid world requires a hierarchical control plane:
- Local autonomy with global policy: Edge agents—such as robotic arms or drones—must make sub-second decisions locally, including navigating obstacles and manipulating objects. These agents operate with onboard models and real-time sensor data, syncing with the cloud only periodically for map updates or mission coordination. Because physical environments are unpredictable and latency-sensitive, agents must respond autonomously without relying on the cloud for each inference.
- Adaptive workload partitioning: Heavy neural operator inference (e.g., object detection, motion planning) can run on-device using optimized accelerators. Meanwhile, larger-scale planning or conversational modules can be executed in the cloud, where a human-in-the-loop may guide overall task goals. Real-time constraints on bandwidth, battery, and latency determine when to offload tasks versus keeping them local.
This distributed design enables real-time operation while accommodating the limited compute and power resources available on edge devices.
Designing Real-Time Systems for Physical AI
Ashutosh Saxena: If we were to design an architecture for robots that can learn, adapt, and act in physical spaces, what principles from large-scale services should carry over? How do we design systems for AI that need real-time coordination across distributed sensors, models, and agents?
Aditya Jami: Three key service-design principles from large-scale distributed systems translate directly to robotics:
- Event-driven microservices: Treat each sensor—camera, LiDAR, IMU, as an independent event source. Use a highly available message bus (e.g., Kafka or ROS 2’s DDS layer) so modules like perception, mapping, and control can subscribe to relevant data and react asynchronously. This loose coupling mirrors how distributed microservices communicate in modern software systems, enabling each module to evolve independently.
- Graceful degradation & circuit breakers: Real-world robotics requires robust failure handling. If a sensor fails or a model degrades (e.g., due to faulty LiDAR input), the system should fall back to alternative sensors or operate in a reduced-capability mode. Inspired by circuit breakers in distributed systems, multi-module architectures should isolate faults and prevent feedback loops, such as mapping and control deadlocking during degraded perception.
- Continuous integration & canary release: New agents—like perception models or motion planners—should first be deployed into digital twin environments for controlled A/B testing. This mirrors the CI/CD pipeline, minimizing the risk of regressions in safety-critical systems.
These principles help bridge the gap between scalable cloud systems and embodied intelligence, laying the foundation for robots that are resilient, upgradeable, and ready for real-world autonomy.
Wikipedia for Robots: Knowledge, Modularity, and APIs
Ashutosh Saxena: One of the projects in robotics that you helped build was a large-scale infrastructure often described as a “Wikipedia for Robots”—RoboBrain. Tell us more about its multimodal APIs—ones that not only return data, but also concepts, embeddings, and action plans. How would infrastructure need to evolve to support this vision at scale?
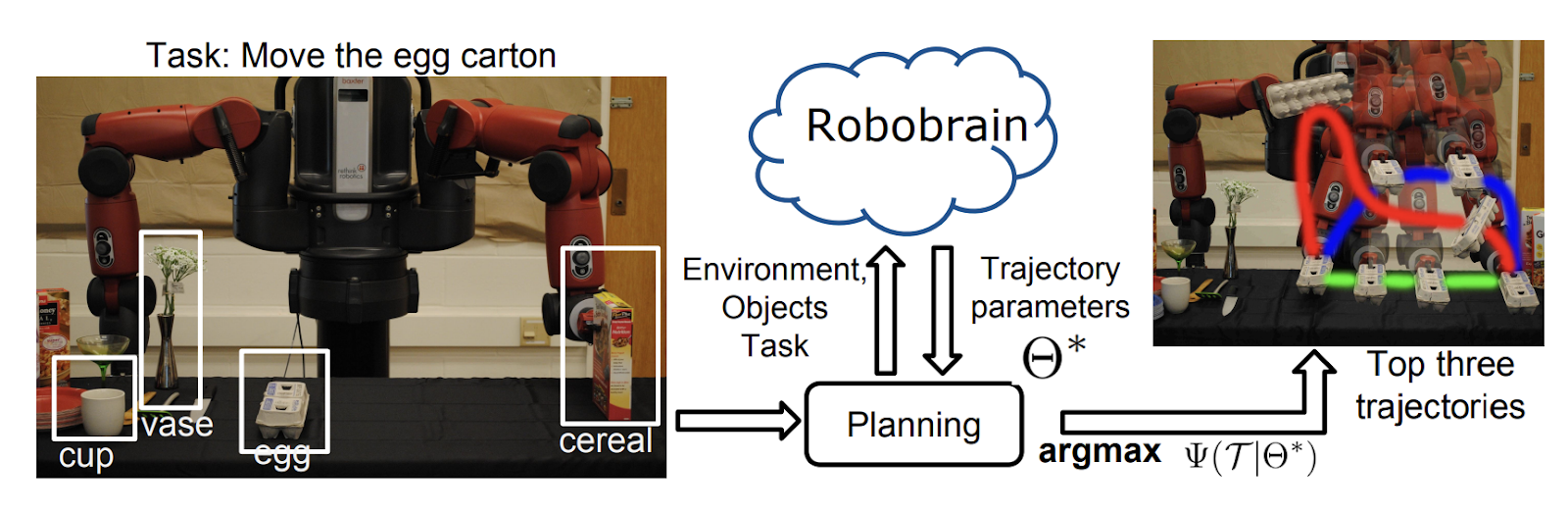
Image source: Ashutosh Saxena, Ashesh Jain, Ozan Sener, Aditya Jami, Dipendra K Misra, Hema S Koppula “RoboBrain: Large-Scale Knowledge Engine for Robots” Published April 12, 2015.
Aditya Jami: RoboBrain was a multimodal knowledge graph built across teams at Stanford, Cornell, and Brown, designed to unify multimodal information—language, vision, and motion—into a common representational space for robots. It offered three primary API layers:
- Concept discovery: A query like “pick up object” returns a graph of relevant object classes, affordances, and semantic relationships—for example, that a "cup" is "graspable." Instead of returning plain text or labels, RoboBrain provides structured knowledge that robots can reason over.
- Embedding lookup: A single API call retrieves vector embeddings across modalities—vision, language, proprioception—mapping diverse sensor inputs into a shared latent space. This shared embedding space enables robots to associate what they see and feel with concepts they've learned elsewhere.
- Policy synthesis: Going beyond static data, RoboBrain could generate parameterized action plans—e.g., “pick up the red cup from the table and pour it into the mug”—that could be grounded in a robot’s motion primitives. These plans were context-aware and reusable across tasks and robots.
In practice, this approach proved effective, as demonstrated by its generalization across various physical platforms. A robot at Cornell could upload a policy to the cloud, and a robot at Brown could download it and execute a novel task it had never encountered before.
To support this at scale, the infrastructure must evolve in three ways:
- Real-time graph indexing enables ultra-low-latency vector search, fused with symbolic reasoning, allowing robots to retrieve relevant knowledge in real-time as they interact with dynamic environments.
- Adaptive sharding: Partition and colocate frequently co-accessed subgraphs and embeddings to minimize latency, especially when transferring knowledge between cloud and edge environments.
- Edge proxies for knowledge caching: Prefetch relevant graph segments and embeddings based on mission context, allowing mobile robots to act on locally available knowledge even when offline or bandwidth-constrained.
This architecture demonstrated the promise of modular, transferable intelligence. It wasn’t just about storing data—it was about enabling robots to generalize across tasks, modalities, and even hardware platforms. That same principle drives what we’re building at TorqueAGI today: foundation models that allow robots to learn once and act anywhere.
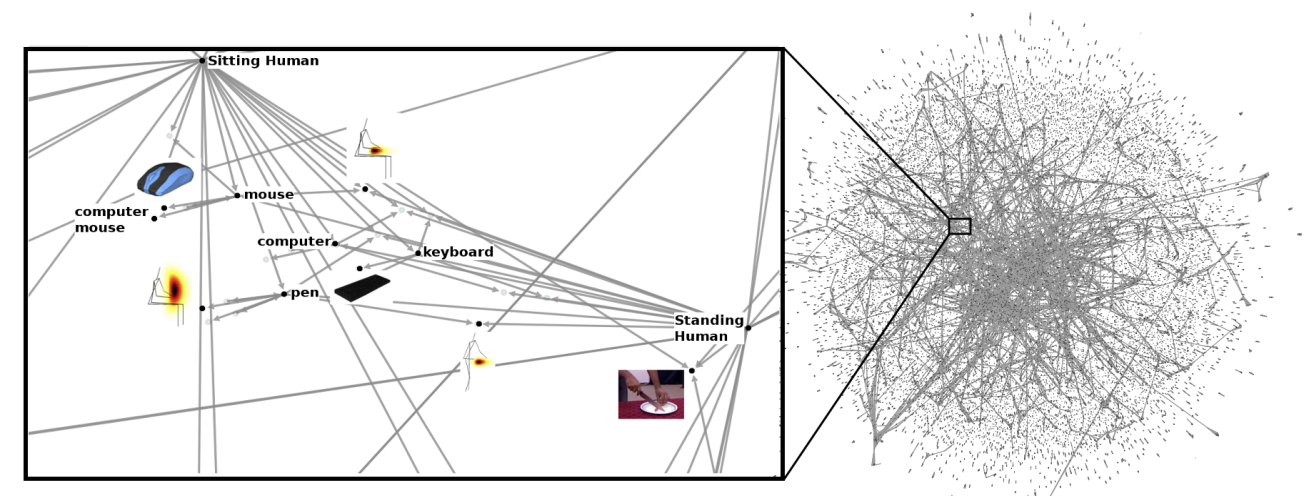
Image source: Ashutosh Saxena, Ashesh Jain, Ozan Sener, Aditya Jami, Dipendra K Misra, Hema S Koppula “RoboBrain: Large-Scale Knowledge Engine for Robots” Published April 12, 2015.
Data and Learning Loops
Ashutosh Saxena: One of the most complex problems in physical AI is data. We can’t scrape the physical world like we scrape the web. What do you see as the role of synthetic data, simulation, or agents learning by performing actions in the environment?
Aditya Jami: Synthetic data becomes a continuous co-processor to real-world data—each feeding the other in a perpetual learning ecosystem. Instead of a one-shot training phase, synthetic and real-world data form a loop that fuels ongoing learning and refinement.
High-fidelity simulators, such as NVIDIA Isaac and Habitat Sim, generate millions of randomized scenes—varying in physics, lighting, textures, and object placements—to teach models environment-agnostic priors through meta-learning. These simulations form the foundation of sim-to-real pipelines, where policies are bootstrapped using off-policy reinforcement learning methods such as SAC or DreamerV3 within digital twins. Once deployed, agents continue learning in the real world, capturing edge cases and failure trajectories that are fed back into training loops for continuous, fleet-wide improvement.
Ashutosh: What’s unique about Physical AI learning?
Aditya Jami: Physical AI requires agents that learn not only from human-defined tasks but also from self-directed experiences.
Active agents explore their environments autonomously, generating synthetic data and updating models as they go. Like AlphaGo, they uncover novel strategies beyond human-defined tasks. Paired with retrieval-to-action loops, these systems evolve from passive responders to adaptive, task-aware copilots, marking a key shift in Physical AI.
Ultimately, our goal at TorqueAGI is to reduce real-world data requirements by 1000x—making agents smarter, faster, and safer through self-supervised, generalizable intelligence.
Personal Reflections
Ashutosh Saxena: Looking back, what’s one principle or lesson from your Netflix and Stanford days that still guides your thinking today?
Aditya Jami: Control Your Chaos Through Declarative Orchestration.
At Stanford’s RoboBrain, we saw the promise of academic innovation—systems that could reason, generalize, and learn across tasks. But it was at Netflix where I learned the importance of industrial-grade engineering: building systems that not only work in theory, but scale reliably under constant change and failure.
That dual perspective shaped my current mindset. Today, every AI system I design begins with a question: How can we declare the desired system state, detect divergence, and automatically reconcile to that state, even in the face of random failure?
Declarative orchestration is key to managing complexity in AI systems. Unlike imperative approaches that define every step, declarative systems specify the desired outcome and let the infrastructure determine the most effective way to achieve it. Even when AI models generate plans autonomously, embedding verifiers ensures those plans align with predictable, controllable behaviors. This philosophy now guides everything from Kubernetes-based model serving and on-device caching to federated learning orchestrators. In AI—especially embodied AI—the goal isn’t to eliminate chaos, but to build systems that can survive, adapt, and thrive within it.
Looking Ahead: From Generative AI to Physical AI
Ashutosh Saxena: What excites you the most about where we’re headed with generative AI systems? And how do you see the potential of physical AI?
Aditya Jami: I’m excited by how we’re moving from passive tools to active collaborators—AI systems that don’t just respond to prompts, but engage proactively with the world.
Right now, many GenAI systems feel like interns with amnesia—you have to tell them what to do, step by step. But the next wave is changing that. We're building task-grounded, context-aware copilots that operate in a self-retrieval-to-action loop. These LLMs won’t just draft content—they’ll invoke APIs, validate outputs against real-time data, adapt to feedback, and even decide what to do next. We’re already pushing in this direction at Meltwater, moving from pure retrieval-augmented generation (RAG) to systems that take actions grounded in data, through tools like MCP.
And this shift doesn’t stop at the screen—it extends into the physical world. Physical AI will inherit these generative capabilities, enabling robots that can explain their reasoning, synthesize plans, and collaborate with humans in complex, real-world environments—from adaptive assembly lines to precision agriculture.
But it’s not just about blending text and motion. What excites me most is the convergence: when cloud-scale LLMs, edge-optimized perception agents, and federated learning loops come together.
In that future, we won’t be prompting AI at every step—we’ll be partnering with it. AI won’t just complete our tasks. It will complete our teams.
Whether you’re dealing with dynamic environments, moving objects, or difficult weather conditions, TorqueAGI is ready to add even more intelligence to your robotic stack. Contact us to schedule a demo and discover how we can assist you.




